
In an ideal world, rotating machinery would operate efficiently and at full-rated speed without ever failing. There would be no unplanned downtime or planned downtime in order to perform maintenance. There would, of course be no safety or environmental incidents as a result of failure. In other words, they would be perfectly reliable. Unfortunately, reliability cannot be achieved without taking proactive steps outside of preventive maintenance; but whatever we do we will never achieve perfect reliability.
Traditionally, maintenance departments needed to develop strategies for dealing with equipment failures. They can simply react to the failures and get very good at returning them to service. They can attempt to detect when failure is occurring and react in a more orderly way. And they can attempt to prevent failure from occurring.
Reacting to the failures, typically referred to as reactive maintenance or breakdown maintenance, is very costly and dangerous; but it is also the most common strategy in industry today.
Detecting the onset of failure is called condition monitoring. Simply monitoring the equipment does not change its inherent reliability, but it does allow us to avoid catastrophic failure.
In this paper, we are going to look at ways of improving reliability as a way of preventing failure. But the phrase “preventing failure” is more complicated than it looks.
Many organizations recognize that they are paying a high cost by reacting to failure and turn to preventive maintenance. But there is confusion over what “preventive maintenance” really means. There is more confusion over whether “preventive maintenance” prevents failure from occurring — or whether it makes failure more likely. And that’s what we need to look at more closely.
What is Preventive Maintenance?
Let’s start by making sure we are all on the same page regarding preventive maintenance. By some definitions, it includes all tasks that may be performed in order to reduce the likelihood of failure. But in the majority of implementations, preventive maintenance is defined as maintenance tasks performed according to some predetermined interval. These are designed to perform restorative or replacement tasks before equipment gets a chance to fail. Preventive maintenance may be best described as interval-based maintenance. The “interval” mentioned could be running hours, distance traveled, production cycles completed or some other interval related to age.
The maintenance tasks performed could be the replacement of bearings or other components. Or the opening and inspection of the machine to determine if repairs or replacement is required. These tasks may have been defined by the manufacturer or regulators. They may have been added to the maintenance plan because of some historical failure. There are also other ways that these tasks may come to be performed. The expectation is that these maintenance tasks are restoring the machine, and therefore we are preventing failure from occurring at a future date. As will soon be shown, in many cases these maintenance tasks actually harm the machine, increasing the likelihood of failure occurring at a future date while at the same time creating opportunities for safety incidents to occur and wasting valuable resources.
We need to explore this in more detail, and to do that, we need to understand why machines fail.
Why Do Machines Fail?
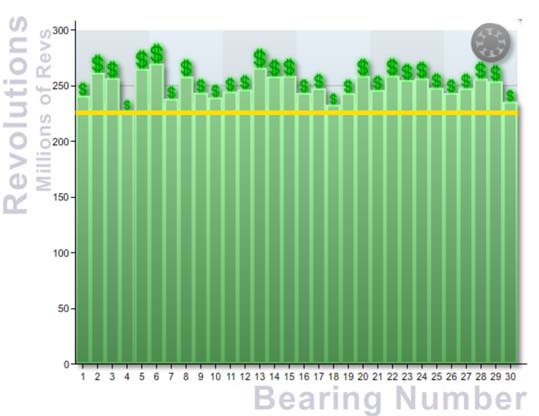
If you were to study how the probability of failure changes with time, you may consider that components such as rolling-element bearings “wear out” at approximately the same rate. For example, if you were to operate 30 bearings over a period of time, you may think that they would all fail at approximately the same time, as depicted in the following graph where the Y-axis is the number of revolutions until failure occurs, and the X-axis is the time-to-failure for each of the 30 bearings.
If we were to plot the probability of failure for a large family of machines with rolling-element bearings over time, you might have suspected a graph shaped like the one below.
The flat region of the graph represents a low probability of failure. At some point in time, the probability of failure increases, and then the machine fails when no action is taken.
Looking at the two graphs above, you could safely replace the bearings after approximately 225 million revolutions, avoid all the failures and not waste any significant residual life of the bearings.
Unfortunately, that is not the reality of the situation.
The first “reality check” is that it is very common for components like bearings to fail early in their life – not long after the machine is commissioned. This can be for a number of reasons, but if we follow precision maintenance practices (summarized later), we can greatly reduce the likelihood of these failures. This region is called “infant mortality” (not a very nice name).
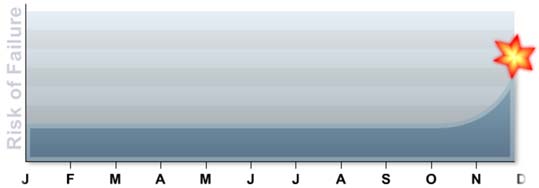
We can update our graph as shown below. This is commonly called a “bathtub” curve.
In reality, the above curve does not follow the reality of most equipment in industrial plants. Yes, the “infant mortality” region is real. What happens later is not the reality for the majority of our machines.
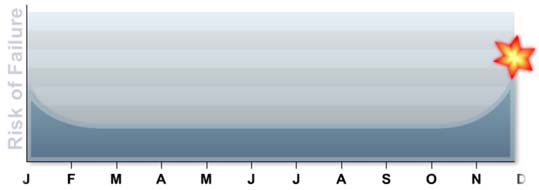
Instead of there being a period of time with a low probability of failure followed by a period of time where the probability of failure is higher, the probability of failure is actually constant over a long period of time. The bearings will fail at “random” times; there is no real way to determine (without condition monitoring) when bearings will fail. The following graph is the actual result achieved when 30 bearings were tested.
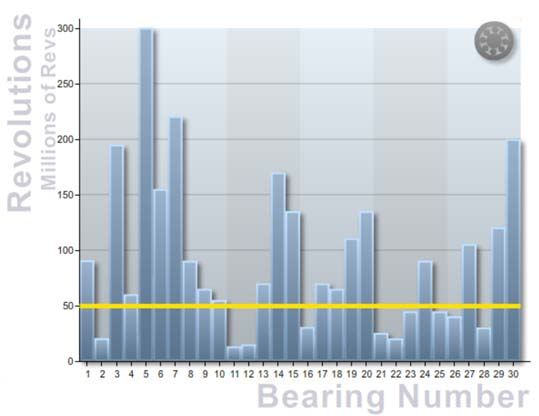
(It is true that we can extend the life of the bearings if we are proactive about design, procurement, maintenance and other factors, but the failures will still be random rather than preventive maintenance.)
Therefore, we can update the graph as shown below. There is the “infant mortality” followed by a period of “random failures.”
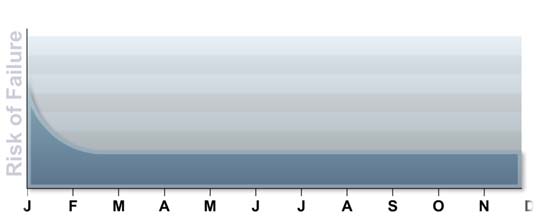
A study was performed in association with United Airlines to examine the failure patterns of a wide range of equipment. This study has been repeated many times in normal industry. The results have always been found to be very similar; the only difference normally relates to the maintenance practices and the percentage of equipment that suffer from infant mortality.
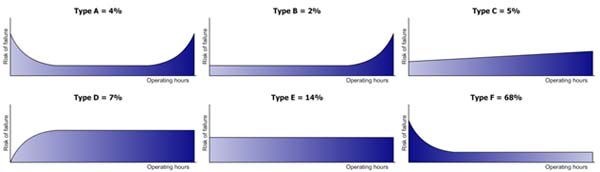
The study concluded that most of the equipment suffers from “random failure.” In the graphs above, Type D, Type E and Type F, representing 89 percent of all equipment failures, all have random failure. The flat region of the graph means there is an equal probability of the failure occurring after one month, one year or 10 years.
What This Means
The bottom line is that it does not make sense to perform interval-based maintenance, i.e., preventive maintenance. If we replace a bearing after two years, for example, we have not improved the likelihood of the equipment running smoothly for the next two years. Statistically, the new bearing is no better than the old bearing. In fact, we have made the situation worse because we will be entering the “infant mortality” region.
Therefore, we have to change our maintenance practices with these failure patterns in mind:
- Do everything possible to reduce the likelihood of failure. This includes operating the equipment properly and conducting proactive maintenance tasks like cleaning and lubrication. This is called “precision operation” and “proactive maintenance.”
- Do everything possible to reduce the likelihood of failure when the machine is installed and commissioned. This reduces the likelihood of infant mortality. It includes the practices used when installing new bearings and aligning machines. This is called “precision maintenance.”
- Test the condition of the equipment to determine if failure will occur in the foreseeable future so that the components in question can be repaired or replaced at a time that is most convenient. This is called “condition-based maintenance.”
- Test the condition of equipment to determine if there is a problem that may cause the machine to fail so that we can prevent failure from occurring. We might call this “proactive condition monitoring.”
- If we cannot cost-effectively determine the condition of equipment via non-intrusive visual inspections or testing with scientific equipment (vibration analysis, infrared analysis, etc.), then it is appropriate to perform interval-based maintenance, i.e., “preventive maintenance.” Of course, we need to know approximately how long it will take a component to fail so that we can determine the optimal time to perform this repair/replacement maintenance action.
- Avoid all of the planned maintenance tasks that can lead to an increased probability of failure. These tasks include intrusive inspections and component replacements mandated due to warranty requirements or a misunderstanding of the failure modes. It is also necessary to:be sure that the design and procurement process prioritizes a:
- reduction in lifecycle costs;
- make sure that we are storing spare parts in a manner that does not degrade their condition;
- and develop optimal planning and scheduling procedures so that the work is performed in the most effective manner.
How to Improve Reliability
There is a great deal that can be done to improve reliability outside of preventive maintenance. Some of it involves the maintenance department, and some of it does not. We need to step back and look at all of the reasons why equipment fails, including the following:
None of these activities are maintenance activities, but there are steps the maintenance department can take, including:
- All maintenance jobs can be properly planned and scheduled.
- All maintenance jobs can be performed with precision. This includes shaft alignment, belt alignment, balancing, tightening and fastening.
- Proactive maintenance tasks should also be performed, such as precision lubrication and frequent cleaning.
In addition, regular non-intrusive inspections should be made, and cost-effective condition monitoring tasks should be performed in order to detect when condition-based maintenance tasks are required.
Defect elimination is a name given to the proactive philosophy of looking for every root cause of equipment failure and proactively seeking to eliminate those root causes, whether they are related the maintenance department or not. This does not mean that we wait for failure to occur and then perform root cause failure analysis. Instead, we learn from industry about all the common reasons why rotating machinery and electrical and process equipment fails. Then, we act proactively to eliminate those root causes.
This is not a simple task, as it involves the majority of the people in the organization, from the highest levels of management through to operators and craftspeople on the plant floor. However, it is an important task and the only way to truly improve reliability as well as achieve the highest levels production, competitiveness, safety and protection of the environment.
Preventive maintenance has a role in industry, but it should not be the dominant strategy. The focus should be on improving the reliability of equipment at every stage of its life.
If the condition of the equipment can be detected cost-effectively, then that is the most appropriate maintenance strategy. When the failure modes are known to be age-related, and the expected trouble-free age of the equipment is well-understood, then interval-based maintenance, or preventive maintenance, is the best strategy. If the interval-based maintenance tasks and condition-monitoring tasks cannot be justified, then a run-to-failure maintenance strategy is appropriate.
Simply relying on preventive maintenance is a costly strategy that will reduce the reliability of the equipment.
This article was previously published in the Reliable Plant 2016 Conference Proceedings.
By Jason Tranter, CMRP, CRL